Evaluating Reliability in Medical DNNs: A Critical Analysis of Feature and Confidence-Based OOD Detection
Harry Anthony & Konstantinos Kamnitsas
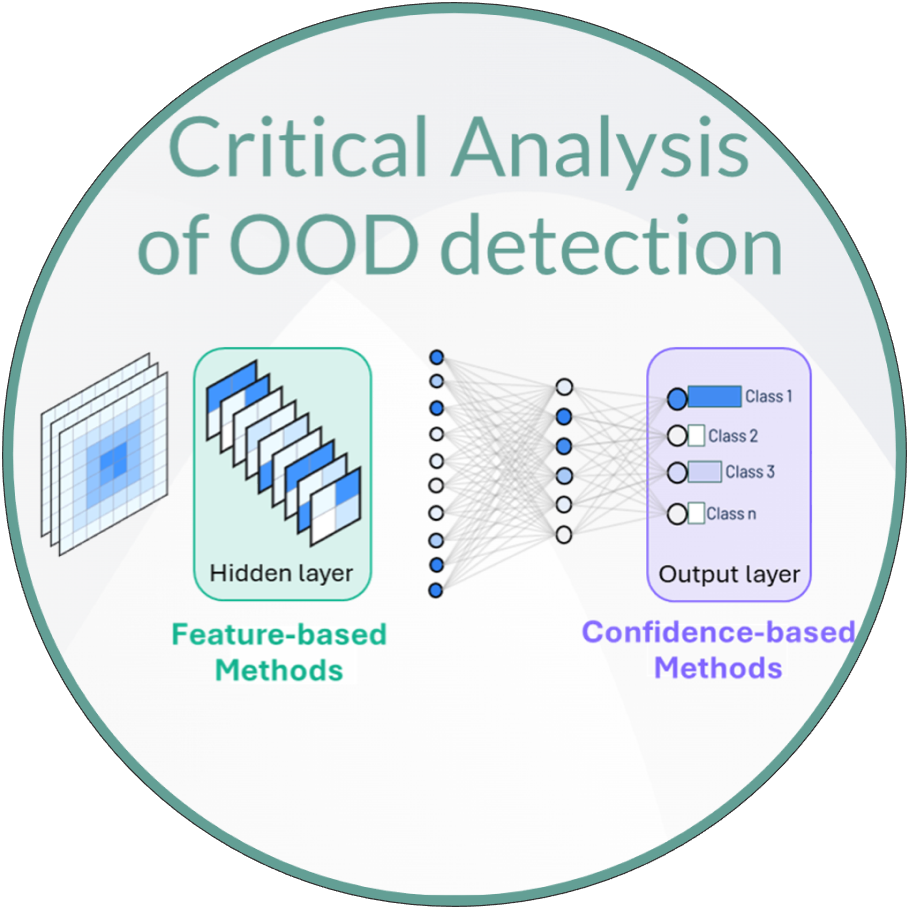
Out-of-distribution detection
and Failure Detection
Consider the setting that we are training a Deep Neural Network (DNN) for medical image classification, such as diagnosing skin lesion images. We have a set of images and corresponding labels that makes up my training data. Once the model is trained, it can be applied to images not seen during training. If the image is from the same distribution as the training data, we call it in-distribution (ID). However, if the image is significantly different from the training data, we call it out-of-distribution (OOD). We see that DNN predictions on OOD data are both unpredictable and unreliable, which motivates the field of out-of-distribution detection - which aims to detect predictions made on OOD data and discard them to improve trustworthiness in the model's predictions.
We analysed post-hoc (which use the parameters or outputs of a pre-trained model) out-of-distribution methods, which we grouped into two groups:
- Confidence-based methods: Which use the model’s output layer for OOD detection.
- Feature-based methods: Which use the model’s hidden layer data for OOD detection.
We evaluated the OOD detection methods on unseen images for 2 criteria:
- OOD Detection: Can the method determine if an input comes from a distribution different from the training data, and consequently discard the model’s prediction for this image?
- Failure Detection: Can the method determine if the model will give an incorrect diagnosis for the input, and consequently discard the model’s prediction for this image?
To study these methods, we created 2 NEW out-of-distribution detection benchmarks:
- D7P (skin lesion dataset): images without rulers are used as training and in-distribution (ID) test data, while images containing rulers are used as out-of-distribution (OOD) test cases
- BreastMNIST (ultrasound dataset): images without annotations are used as training and in-distribution (ID) test data, while images containing annotations are used as out-of-distribution (OOD) test cases. These benchmarks are available on my GitHub repository if you would like to use this benchmark in your own research.

Studying the results, we see that:
- Confidence-based methods outperform feature-based methods at Failure Detection.
- Feature-based methods outperform confidence-based methods at Out-of-distribution Detection.
But why do these trends occur? To study this, we created counterfactual data by synthetically removing the OOD artefact from each OOD image in our benchmarks. We did this using intra-image interpolation, where we use a patch from the same image. These counterfactual images are available on my GitHub repository if you would like to use them in your own research, where you can find more details on how this data was made.
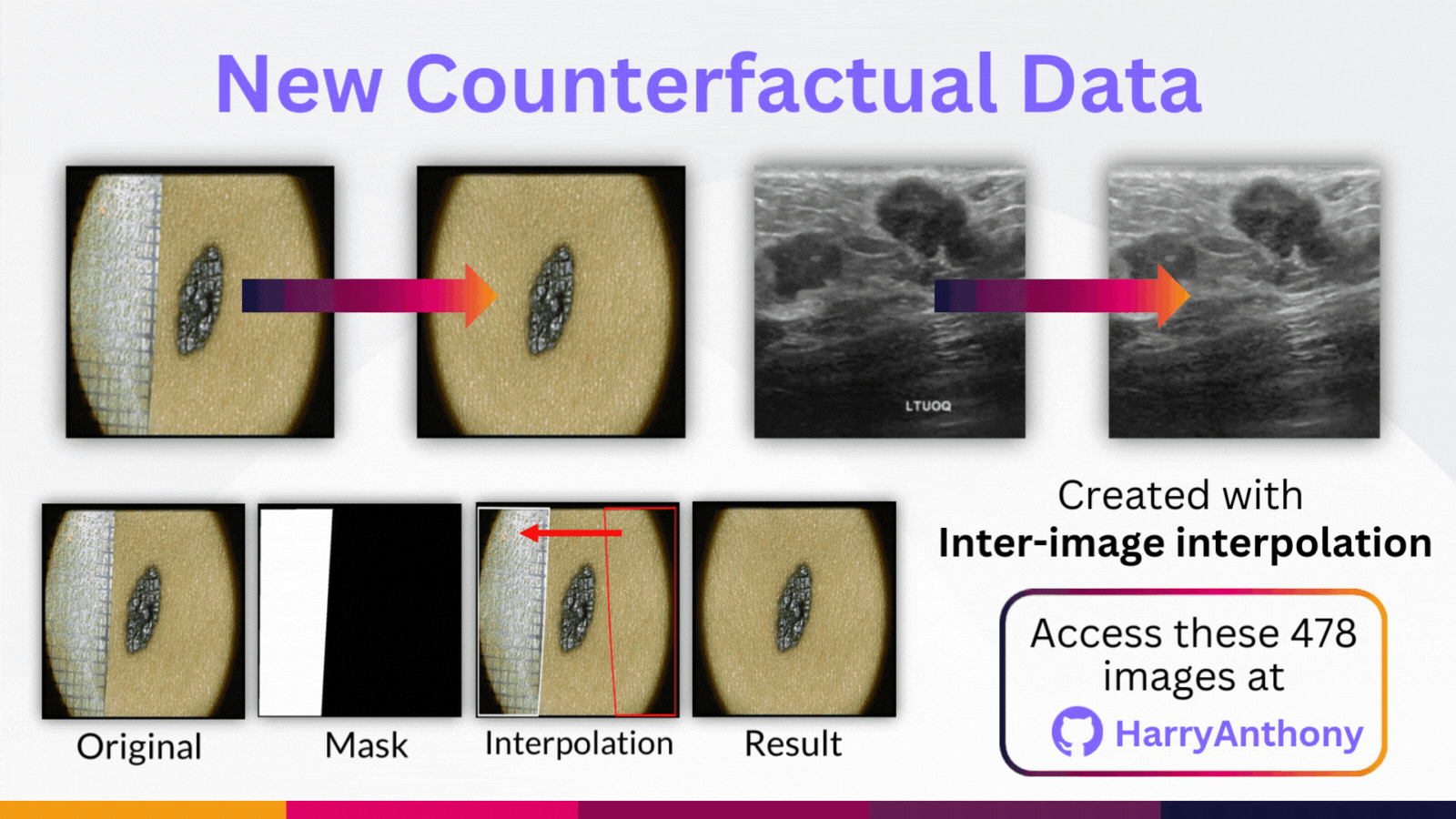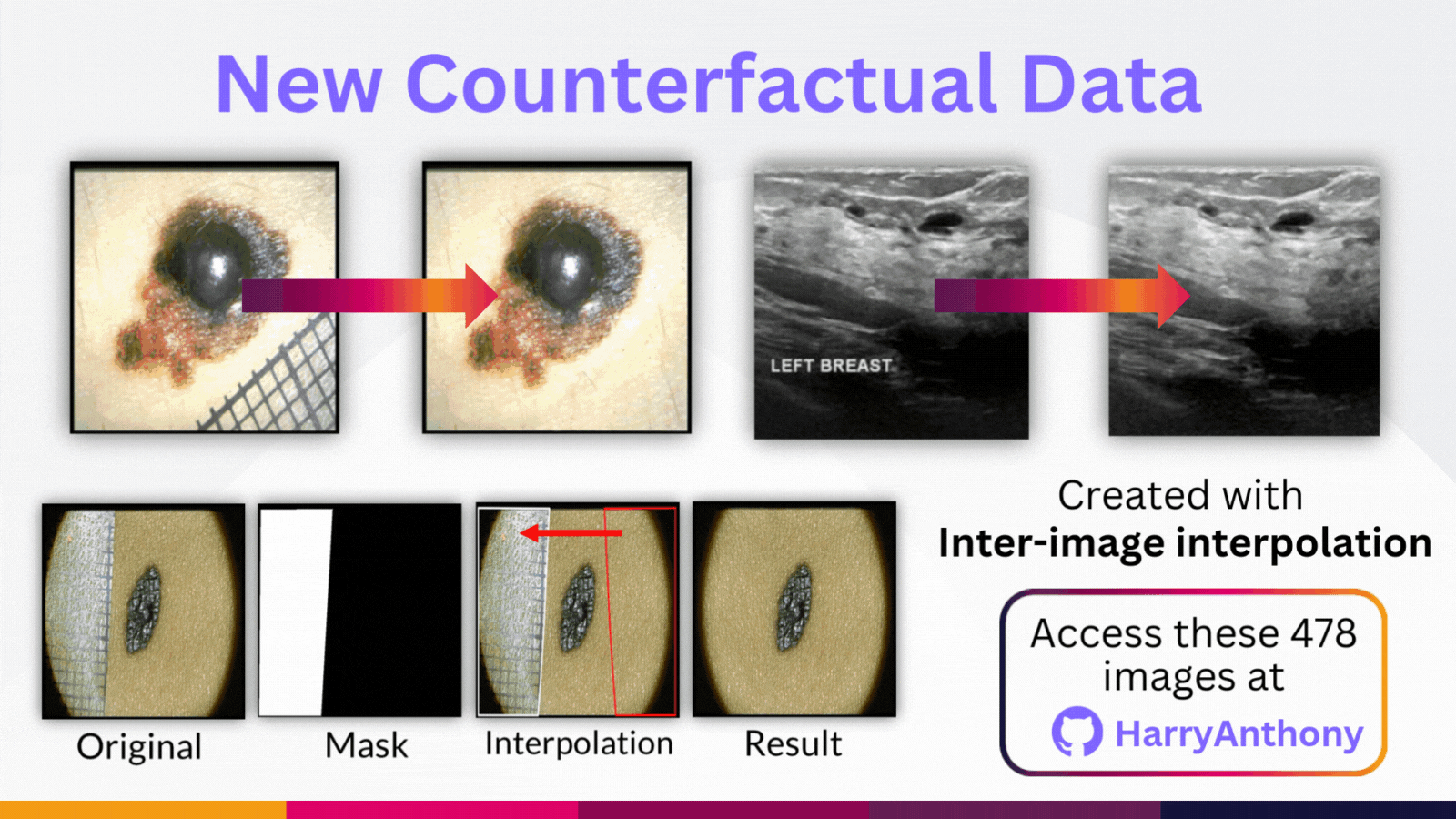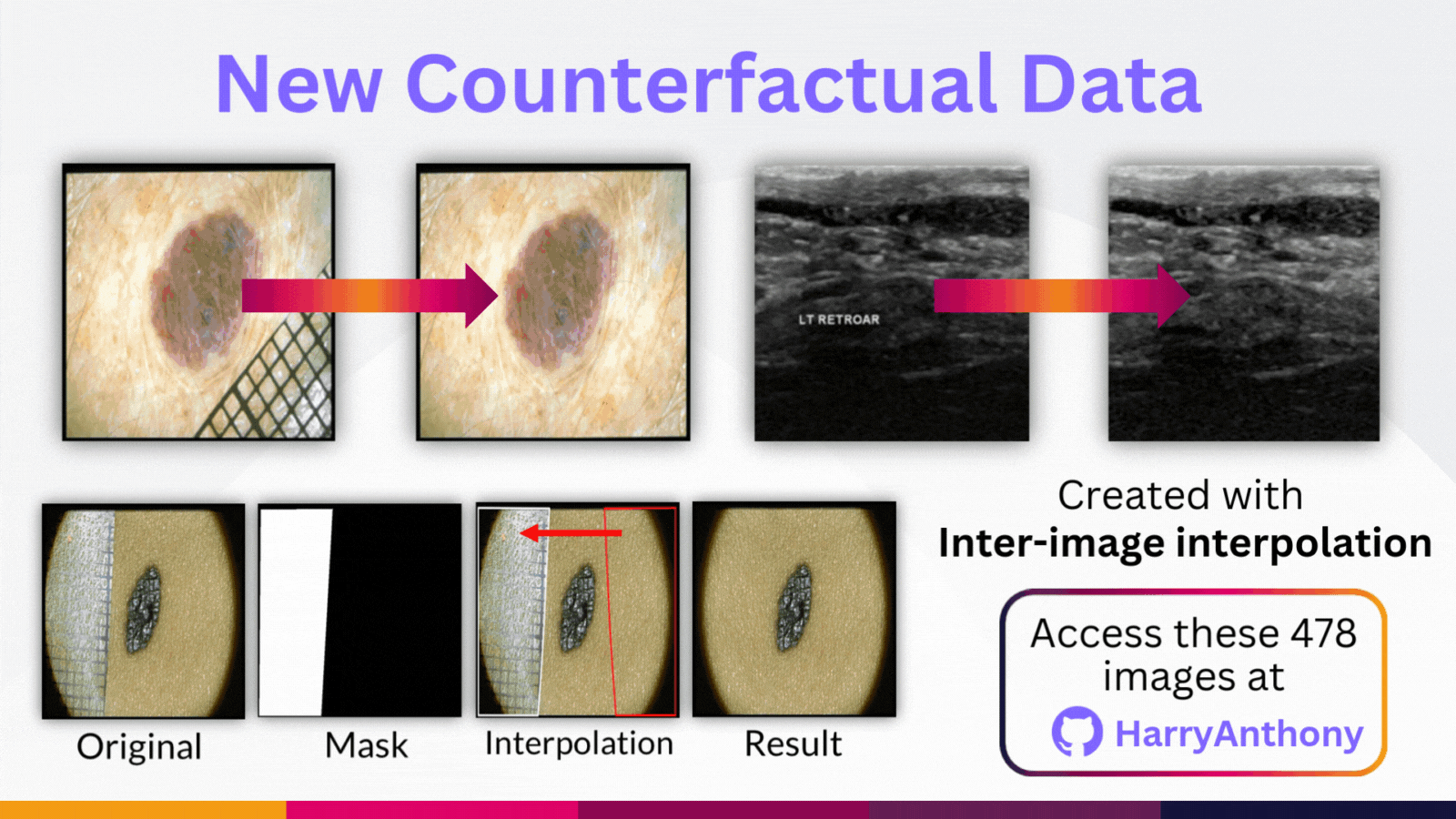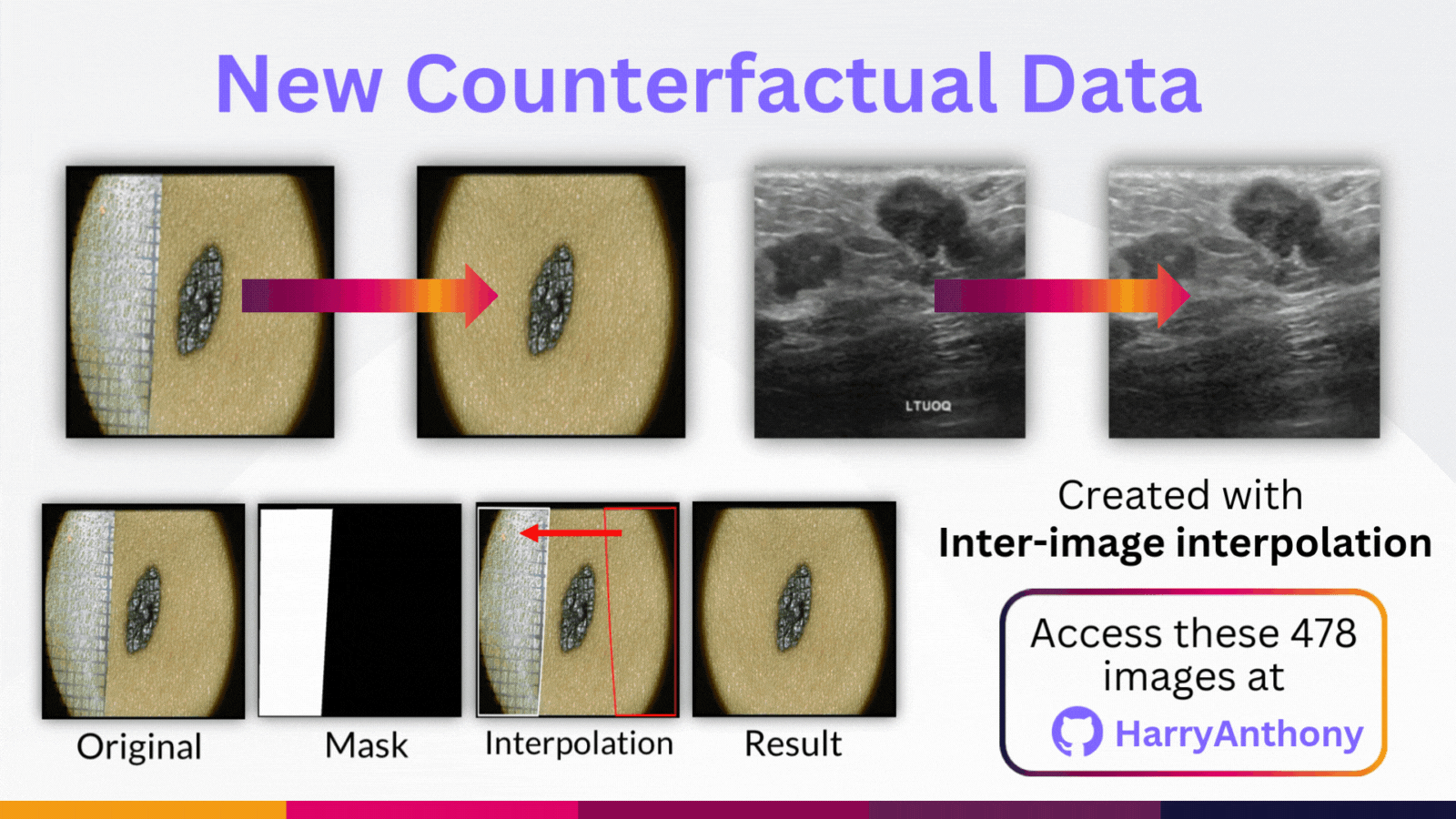
We then studied the model predictions and the eXplainable AI heatmaps (using LRP), both with and without the OOD artefact. What we observe is OOD artefacts can cause HIGH-confidence diagnoses! But confidence-based methods assume OOD artefact should lead to high entropy outputs, and this mismatch is a key reseason why confidence-based methods have poor OOD detection performance.
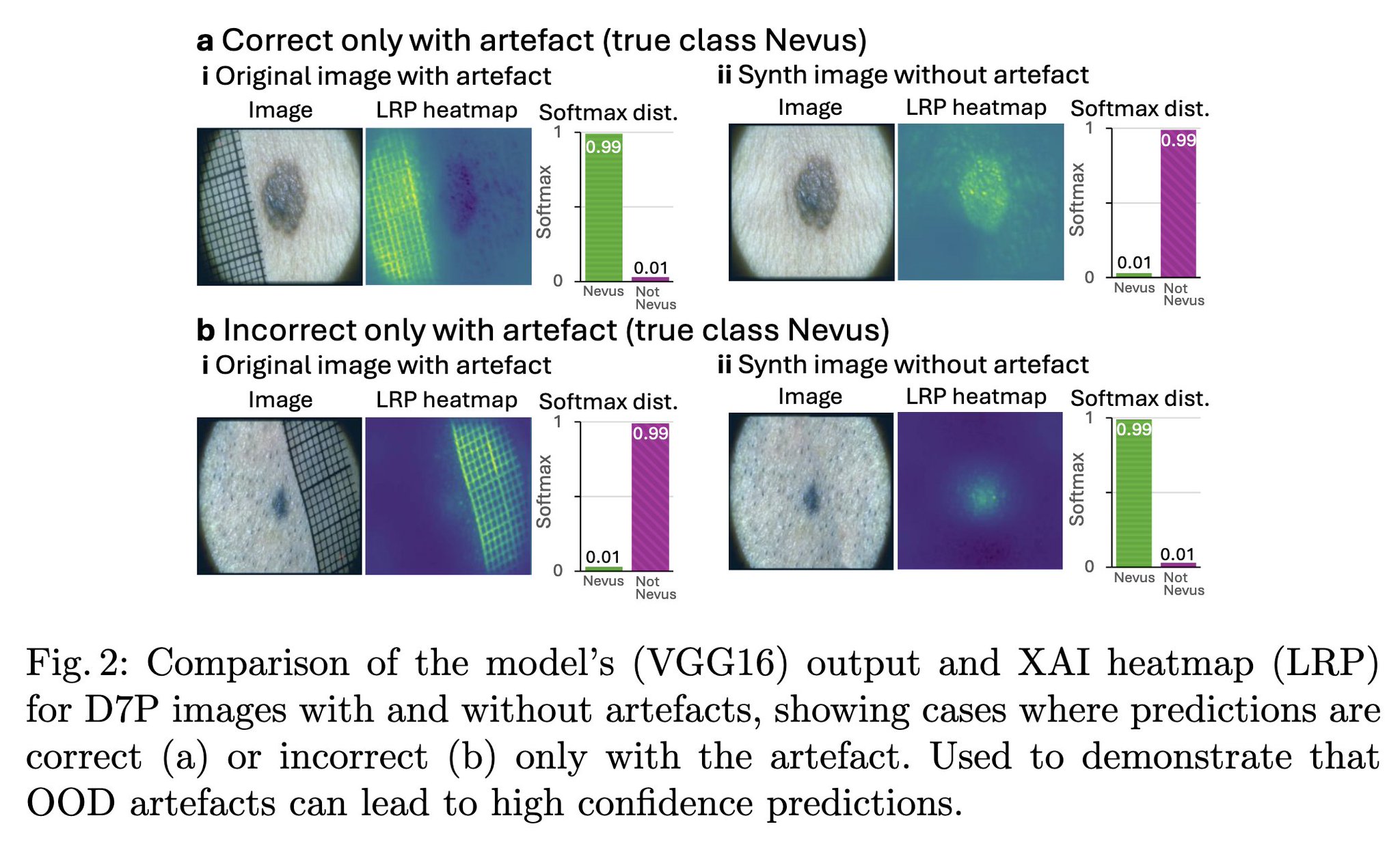
We then studied the counterfactual datasets, looking at the model predictions both with and without the OOD artefact, and grouped the data into four categories:
- Correct regardless
- Incorrect regardless
- Correct only with artefact
- Incorrect only with artefact.
We can then study what happens when we apply OOD detection methods. We study both a confidence-based method (MCP) and a feature-based method (Mahalanobis Score). We first calculate the scoring function for each test image, we then apply a threshold at the 75 percentile of the held-out ID data, and discard all diagnoses below the threshold. Looking at the results, we see that the strengths of one method, is the weakness of another. This motivates us to combine BOTH a confidence-based method and a feature-based method to mitigate against their weaknesses. We see that combining these methods results in more trustworthy predictions, but with a higher dismissal rate.
Dive into our research!

| 📄 Paper | 📊 Poster | </> Code |